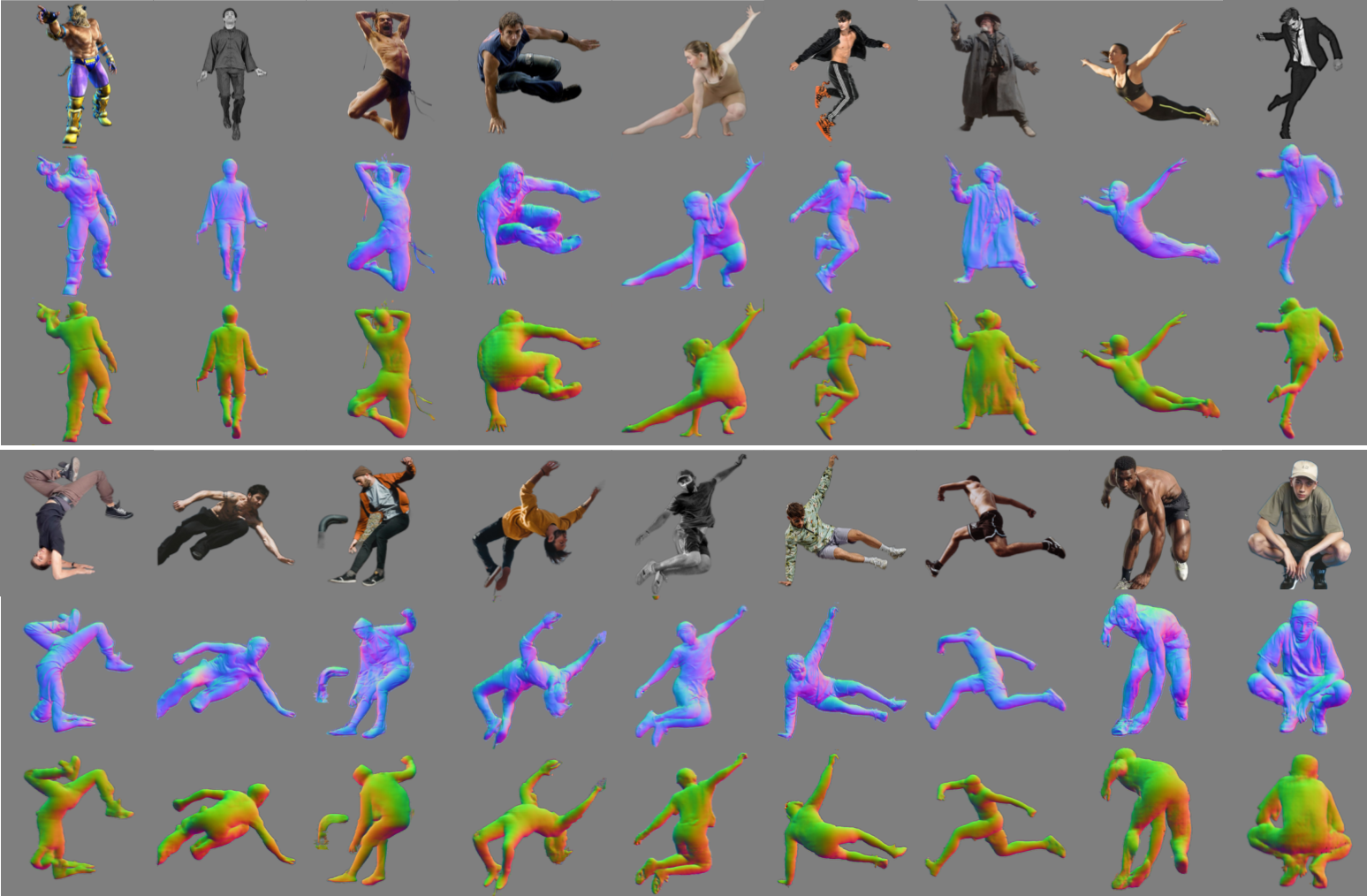ICON: Implicit Clothed humans Obtained from Normals
1Max Planck Institute for Intelligent Systems
2University of Amsterdam
CVPR 2022
Paper |
Code |
Keynote |
Poster |
Colab |

HuggingFace |
Paper |
Code |
Keynote |
Poster |
Colab |
HuggingFace |
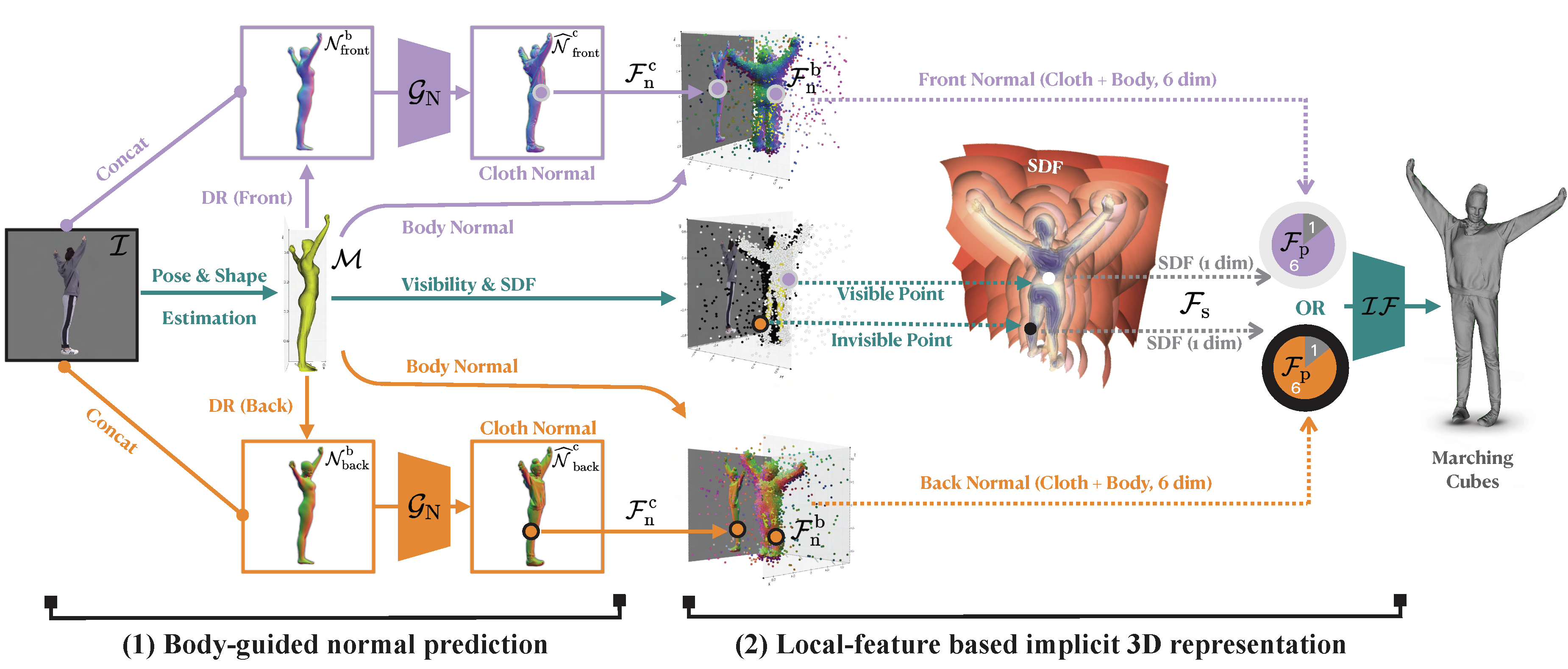
-loop_clothICON takes, as input, an RGB image of a segmented clothed human and a SMPL body estimated from the image. The SMPL body is used to guide two of ICON’s modules: one infers detailed clothed-human surface normals (front and back views), and the other infers a visibility-aware implicit surface (iso-surface of an occupancy field).
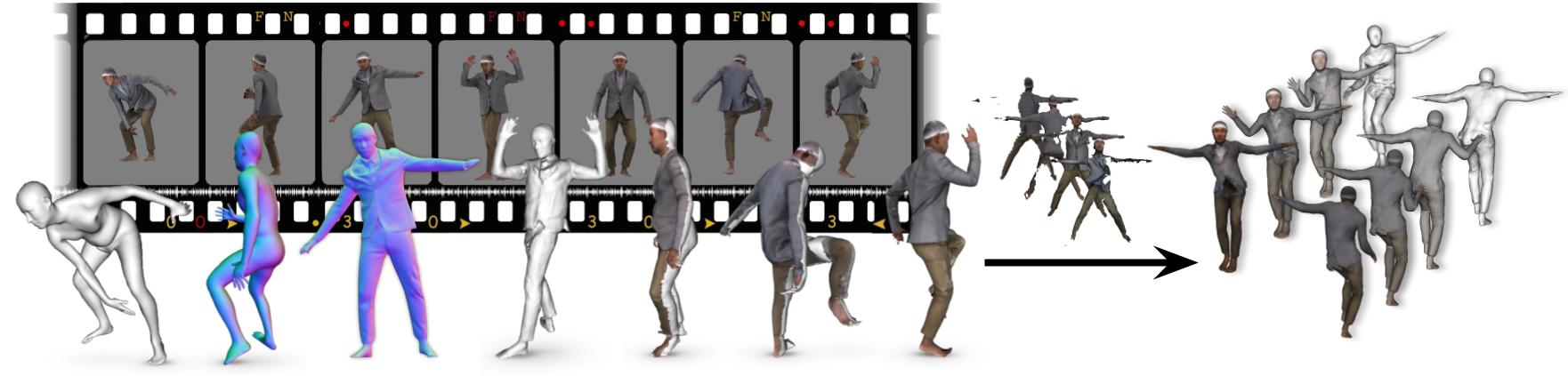
Errors in the initial SMPL estimate, however, might misguide inference. Thus, at inference time, an iterative feedback loop refines SMPL (i.e. its 3D shape, pose and translation) using the inferred detailed normals, and vice versa, leading to a refined implicit shape with better 3D details.
We thank Yao Feng, Soubhik Sanyal, Qianli Ma, Xu Chen, Hongwei Yi, Chun-Hao Paul Huang, and Weiyang Liu for their feedback and discussions, Tsvetelina Alexiadis for her help with the AMT perceptual study, Taylor McConnell for her voice over, Benjamin Pellkofer for webpage, and Yuanlu Xu's help in comparing with ARCH and ARCH++.
Special thanks to Vassilis Choutas for sharing the code of bvh-distance-queries
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No.860768 (CLIPE Project)
MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH. While MJB was a part-time employee of Amazon during this project, his research was performed solely at, and funded solely by, the Max Planck Society.
@inproceedings{xiu2022icon,
title = {{ICON}: {I}mplicit {C}lothed humans {O}btained from {N}ormals},
author = {Xiu, Yuliang and Yang, Jinlong and Tzionas, Dimitrios and Black, Michael J.},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {13296-13306}
} For more questions, please contact icon@tue.mpg.de
For commercial licensing, please contact ps-licensing@tue.mpg.de
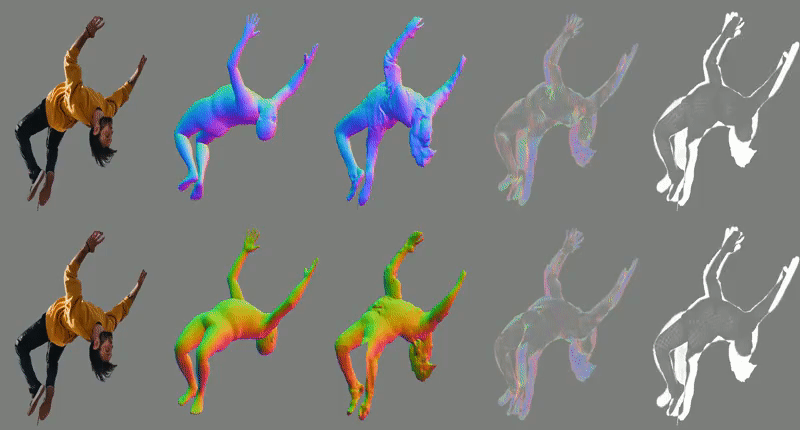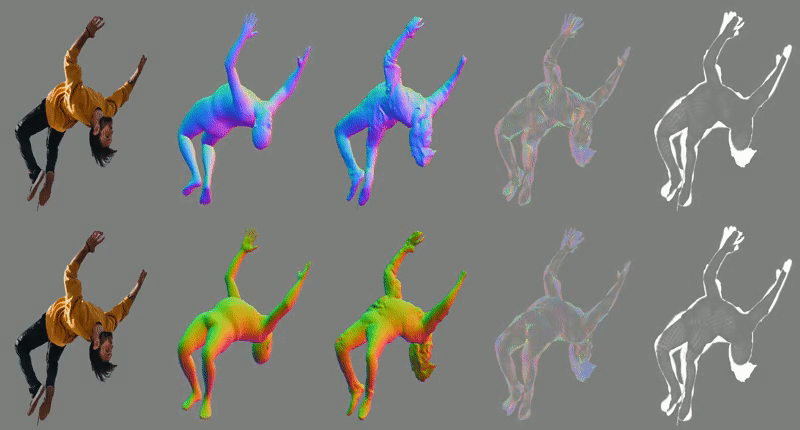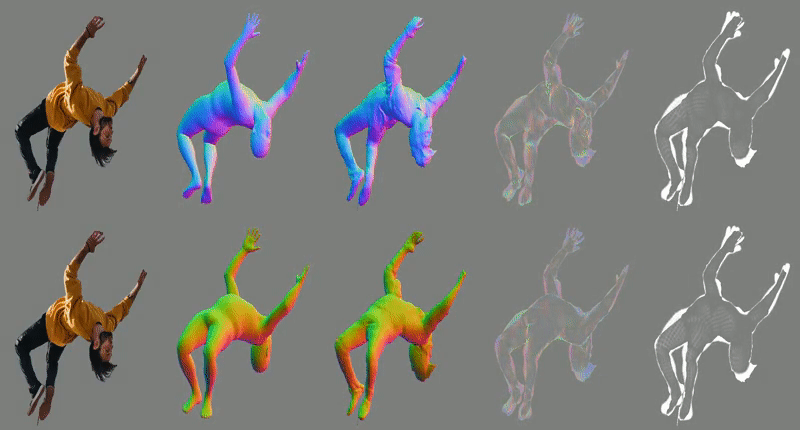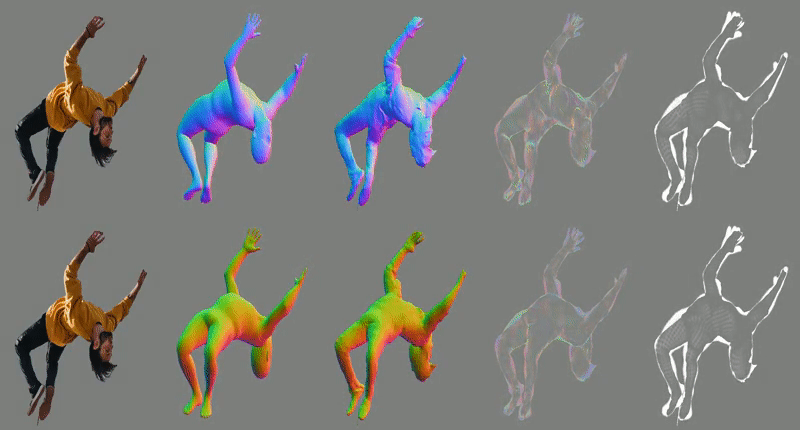

.gif)